In this post, I tried to show most of the Hive components and their dependencies from old Hive version to new Hive version. I made a single architecture diagram which may help you to visualize complete Hive overall architecture including common client interfaces. I tried to keep post contents very little other than a big diagram. So, it will help you to visualize instead of regular reading and forget (in my case 🙂 ). It included HiverServer1 and HiveServer2 as well. HiveServer2 is a rewrite of HiveServer1 (sometimes called HiveServer or Thrift Server) that addresses Multi-client concurrency and authentication problems which I will discuss later in this post, starting with Hive 0.11.0. Use of HiveServer2 is recommended.
HiveServer1 and HiveServer2 is built on Thrift (one of the cross-language serialization/RPC framework which support communication between variety of programming languages). Click on the diagram image for better clarity or zoom the image.

HiveServer1 Concurrency Problem:
HiveServer (aka HiveServer1) implementation has concurrency bugs. In fact, it’s impossible for HiveServer1 to support concurrent connections using the current Thrift API, but the current Thrift API does not provide explicit support for sessions or connections, HiveServer1 has no way of mapping incoming requests to client sessions, which makes it impossible for HiveServer1 to maintain session state in between calls.
Problem-1: Current Thrift API does not provide explicit support for sessions between client application and Hive which makes it impossible for HiveServer (aka HiveServer1) to maintain session state in between calls. Find the problem steps below:
Step-1: User-1 open Connection-1.
Step-2: Thrift assign a WorkerThread-1 for Connection-1.
Step-3: User-1 SET a variable in a call.
Step-4: User-1 execute a query in another call based on previously set value. Value is lost.
Step-5: Thrift does not maintain session between calls.
Solution-1: Attempts to maintain session state using thread-local variables and relies on Thrift to consistently map the same connection to the same Thrift worker thread. This raise another problem (problem-2).
Problem-2: Current Thrift API can not recognize user disconnect.
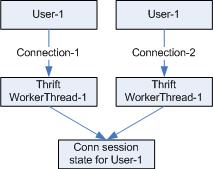
Step-1: User-1 open Connection-1.
Step-2: Thrift assign a WorkerThread-1 for Connection-1.
Step-3: User-1 do some actions.
Step-4: User-1 close Connection-1.
Step-5: Thrift does not recognize disconnection.
Step-6: User-1 create a new Connection-2.
Step-7: Thrift assign the same WorkerThread-1 to Connection-2 for User-1.
Step-8: So, User-1 can see the previous changes which is not expected.
Solution-2: Modifying Thrift to allow HiveServer1 to directly map client’s logical session (duration between HiveServer1.open() and HiveServer1.close() call) with physical connection. That is, keep the physical connection open till client call HiveServer1.close(). This raise again another problem (problem-3).
Problem-3: This approach makes it really hard to support HA since it depends on the physical connection lasting as long as the user session, which isn’t a fair assumption to make in the context of queries that can take many hours to complete.
Solution-3: Instead, the approach taking with HiveServer2 is to provide explicit support for sessions in the client API, e.g every RPC call references a session ID which the server then maps to persistent session state. This makes it possible for any worker thread to service any request from any client connection, and also the avoids the need to tightly couple physical connections to logical sessions.
At last not least, I am requesting all my visitors to provide your valuable feedback including correctness to better this blog post.

Very much indepth explaination
LikeLike
Very nice detailed explanation
LikeLike