Blocks are physical division and input splits are logical division. One input split can be map to multiple physical blocks. When Hadoop submits jobs, it splits the input data logically and process by each Mapper task. The number of Mappers are equal to the number of splits. One important thing to remember is that InputSplit doesn’t contain actual data but a reference (storage locations) to the data. A split basically has 2 things :
a length in bytes and a set of storage locations, which are just hostname strings.
Block size and split size is customizable. Default block size is 64Mb and default split size is equal to block size.
1 data set = 1….n files = 1….n blocks for each file
1 mapper = 1 input split = 1….n blocks
InputFormat.getSplits() is responsible for generating the input splits which are going to be used each split as input for each mapper. By default this class is going to create one input split for each HDFS block.
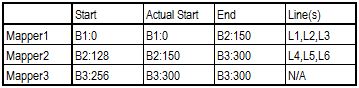
Suppose my data set is composed on a single 300Mb file, spanned over 3 different blocks (block size is 128Mb), and suppose that I have been able to get 1 InputSplit for each block.
File is composed on 6 lines of 50Mb each
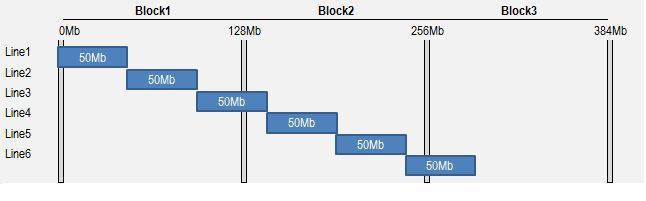
- The first Reader will start reading bytes from Block B1, position 0. The first two EOL will be met at respectively 50Mb and 100Mb. 2 lines (L1 & L2) will be read and sent as key / value pairs to Mapper 1 instance. Then, starting from byte 100Mb, we will reach end of our Split (128Mb) before having found the third EOL. This incomplete line will be completed by reading the bytes in Block B2 until position 150Mb. First part of Line L3 will be read locally from Block B1, second part will be read remotely from Block B2 (record boundaries must be respected), and a complete record will be finally sent as key / value to Mapper 1.
- The second Reader starts on Block B2, at position 128Mb. Because 128Mb is not the start of a file, there are strong chance our pointer is located somewhere in an existing record that has been already processed by previous Reader. We need to skip this record by jumping out to the next available EOL, found at position 150Mb. Actual start of RecordReader 2 will be at 150Mb instead of 128Mb.
We can wonder what happens in case a block starts exactly on a EOL. By jumping out until the next available record (through readLine method), we might miss 1 record. Before jumping to next EOL, we actually need to decrement initial “start” value to “start – 1″. Being located at at least 1 offset before EOL, we ensure no record is skipped !
Remaining process is following same logic, and everything is summarized in below table.
Let say I have a 1 GB file name fileA.txt. My default HDFS block size is 64 MB.
I issue the following command:
$ hadoop -fs copyFromLocal fileA.txt input/data/
The above command copies the file fileA.txt from your local machine to input/data directory in HDFS:
You have 16 blocks to be copied and replicated ( 1 GB / 64 MB = 16 ).
If you have 8 datanodes, a single datanode might not have all blocks to reconstitute the file.
when I issue the following command
$ hadoop -fs cat input/data/fileA.txt | head
So, when client issues ‘cat’ command to Hadoop, then basically client sends a request to NameNode that — “I want to read fileA.txt, please provide me the locations of all the blocks of this file stored at various locations”. It’s duty of NameNode to provide the locations of the blocks stored on various DataNodes.
Based on those locations, client directly contacts with DataNodes for those blocks. And finally client reads all those blocks in same order/manner those blocks were stored (here NameNode returns the addresses of all the blocks of a file to the client) in HDFS–resulting in complete file to the client.
Example 1 : File size is 900 MB and block size is 64 MB
Number of blocks required = (900 / 64) MB = 14.07 = 15 blocks (last block will contain only .07 MB data). Each block in HDFS is stored as a file in the Data Node. So, there will be 15 files. 14 file size will be 64 MB each but last file (15th file) size will be .07 MB only. Every file (HDFS block) in HDFS is represented as an object in the NameNode’s memory which is the meta-data of the file, each of which occupies 150 bytes memory, as a rule of thumb. So, there will be 15 objects created and each occupy 150 bytes memory and will occupy total = 15 * 150 bytes = 2250 bytes (2.2 KB) NameNode’s memory.
How to check number of blocks for a file, block size, block sequence, block names and block locations:
$ hadoop fsck /path/to/file -files -blocks -locations
Sample Output:
FSCK started by bsen from /121.215.131.201 for path /user/bsen at Wed Mar 11 10:43:13 EDT 2015
/user/bsen <dir>
/user/bsen/fileA.txt 7420270 bytes, 8 block(s):
0. blk_3659272467883498791_1006 len=1048576 repl=3 [121.215.131.202:50010]
1. blk_-5158259524162513462_1006 len=1048576 repl=3 [121.215.131.203:50010]
2. blk_8006160220823587653_1006 len=1048576 repl=3 [121.215.131.204:50010]
3. blk_4541732328753786064_1006 len=1048576 repl=3 [121.215.131.205:50010]
4. blk_-3236307221351862057_1006 len=1048576 repl=3 [121.215.131.206:50010]
5. blk_-6853392225410344145_1006 len=1048576 repl=3 [121.215.131.207:50010]
6. blk_-2293710893046611429_1006 len=1048576 repl=3 [121.215.131.208:50010]
7. blk_-1502992715991891710_1006 len=80238 repl=3 [121.215.131.209:50010]

A very good explanation ! Thanks !
LikeLike
xzvcvc
LikeLike
Dear Author, thank for your post. I benefit from your posts a lot. They are very useful.
On this post, in example 1 and 2, you said that there are 64MB and 24MB space wasting.
I thought that, the characteristics of HDFS is not like opeating system’s file system. That means it does not waste any space if the block size is not fix to the declared block size.
” Unlike a filesystem for a single disk, a file in HDFS
that is smaller than a single block does not occupy a full block’s worth of underlying
storage. (For example, a 1 MB file stored with a block size of 128 MB uses 1 MB of disk
space, not 128 MB.) When unqualified, the term “block” in this book refers to a block in
HDFS.” (cited from book Hadoop – The Definitive guide, page 66, section HDFS block)
Please kindly explain to me your meaning.
I am very appreciate about this
Thank you very much
Yours sincerely,
Bean
LikeLike
Thank! you for your valuable comment. You are right that HDFS block is not about physical OS block. The block division in HFDS is just logically built over the physical blocks of underlying OS filesystem. Each block in HDFS will make an entry into NameNode’s memory (RAM). So, small HDFS block size will make burden on NameNode’s memory. I have updated my post content based on this.
LikeLike
Thank you very much. I am very interesting on your post. If you have time, please kindly post some deep contain about Hadoop, such post like [https://hadoopabcd.wordpress.com/2015/05/31/deep-drive-understanding-namenode/] is very helpful. Can you make similar post for datanode, RM, NM, etc. Thank you very much. I am waiting for your posts.
LikeLike