In Hadoop 1.x, there is only one NameNode (i.e allow only one Active NameNode) in a cluster, which maintains a single namespace (single directory structure) for the entire cluster. Regarding that Hadoop cluster is becoming larger and larger one enterprise platform and stores the entire file system metadata is in NameNode memory (RAM), when there are more data nodes with many files, the NameNode memory will reach its limit and it becomes the limiting factor for cluster scaling (limiting number of files store in the cluster). Hadoop 1.x, the namespace can only be vertically (add more RAM) scaled on a single NameNode.
In Hadoop 2.x release series, it introduces HDFS Federation (a federation of multiple Active NameNodes that statically partition/divide the filesystem namespace and each Active NameNode contain only one partition/portion), which allows a cluster to scale by adding more NameNodes horizontally, each of which manages a portion of the filesystem namespace. NameNodes are federated, that is, all these NameNodes work independently and don’t require any co-ordination with each other.
Each DataNode registers with all the NameNodes in the cluster and can store the data blocks for multiple NameNodes by logically partition (block pool) disk for each NameNode and send periodic heartbeats and data block report to all NameNodes. Each NameNode is responsible for two tasks: Namespace management and Block Management.
Key Benefits:
- Scalability – HDFS cluster storage (DataNodes) scales horizontally but the namespace does not. Large deployments using lot of small files benefit from scaling the namespace by adding more NameNodes to the cluster.
- Performance – Adding more NameNodes to the cluster scales/improve the file system read/write operations throughput.
- Isolation – A single NameNode offers no isolation in multi user environment. A test application can overload the single NameNode and slow down production critical applications. With multiple NameNodes, different categories of applications and users can be isolated/differentiated to different namespaces.
- Single View – Client side mount tables/ViewFS for integrated views. HDFS client can view multiple namespace into a single namespace through mount at client side. So, client can see only one namespace.
Key Terms:
- Metadata – Metadata consists of file name, creation date, file block locations, permission etc.
- Namespace– It consists of files, directories and file block locations. Namespace operation are creation of files, deletion of files, renaming of files, listing of files etc. It maintain at NameNode. Suppose we have two machines acting as namenodes as first namenode (NN1) handles all files under namespace /finance, ie all data of finance department. Similarly second namenode(NN2) handles data of accounts department under namespace /accounts.
- Block Management – It manages file blocks stored in DataNodes. It perform block addition, block deletion, listing of blocks, block replication etc. Also all DataNodes are registered here. It maintain at NameNode.
- Block Storage – It stores all physical file blocks. Block storage maintain at DataNode.
- Block Pool – A Block Pool is a set of blocks that belong to a single namespace. Each DataNode store all the block pools for all NameNodes in the cluster. Each Block Pool is managed independently. This allows a namespace to generate Block IDs for new blocks without the need for coordination with the other namespaces. A NameNode failure does not prevent the DataNode from serving other NameNodes in the cluster.
- Namespace Volume – A Namespace and its block pool together are called Namespace Volume. DataNodes store blocks in Block Pools for all the Namespace Volumes. When a Namenode/namespace is deleted, the corresponding block pool at all the DataNodes is deleted.
- Cluster ID – A ClusterID identifier is used to identify all the nodes in the cluster. This ID should be used for formatting the NameNodes into the cluster.

Just to get more clarity – in case NameNode NN-1 in above diagram goes down, Pool-1 also will be unavailable. So the datanode blocks maintained in Pool-1 will be inaccessible until the Namenone NN-1 is restored.
If we see the above diagram NS1, NSk… NSn are the name spaces which contains the directories, blocks.. name space is nothing but, In case if you want to segregate your data like all marketing related information into marketing folder, sales related information into sales folder, we do this by name space.
Pool-1, Pool-k,…Pool-N are the block pools which stores the blocks related information of that corresponding name space. each pool is associated to its own name space.
Block Pool:
- DataNodes store blocks in Block Pools for all the Namespace Volumes.
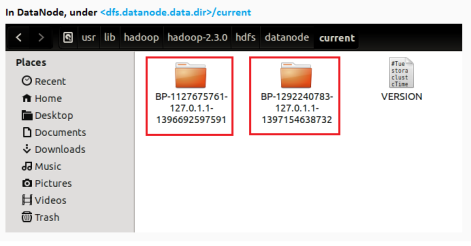
- You can find all block pools (as directory) in DataNodes under dfs.datanode.data.dir
- Block pool: Cluster is balanced if each block pool in each datanode is balanced.
To delete a block pool:
$ hdfs dfsadmin -deleteBlockPool <datanode-host:port> blockpoolId
Block pool directory for the given blockpool id on the given datanode is deleted along with its contents. A Sample block pools in a DataNode

Memory Usages in NameNode:
The maximum number of files in HDFS depends on the amount of memory available for the NameNode. Each file object and each block object takes about 150 bytes of the memory, as a rule of thumb. Thus, if you have 10 million (1,000,000,0) files and each file has 1 block each, then you would need about 3GB of memory for the NameNode:
1GB = (1024 * 1024 * 1024) bytes = 1,073,741,824 bytes
3GB = (1,073,741,824 * 3) bytes = 3,221,225,472 bytes
1 file + 1 block = (1 * 150) bytes + (1 * 150) bytes = 300 bytes
1,000,000,0 files + 1,000,000,0 blocks = (1,000,000,0 * 150) bytes + (1,000,000,0 * 150) bytes = 3,000,000,000 bytes (approx 3GB)
Summary:
- Helps overcome the limit of how much metadata the NameNode can store in memory by splitting it up across multiple NameNodes. This gives us one logical namespace from a bunch of different NameNodes. Similar to the Linux filesystem where many different devices can be mounted to different points, but still form under one named root /.
- Each datanode has a block pool for each namespace. While blocks from different pools are stored on the same disks (there is no physical separation), they are logically exclusive. Each datanode sends heartbeats and block reports to each NameNode.
- NameNodes do not communicate with one another and failure of one does not affect the other.
- Clients view the namespace via an API implementation called ViewFS. This maps slices of the filesystem to the proper NameNode. It is configured on the client side via the local core-site.xml file.
- Federation does not support overlapping mount points as of right now.

[…] Solution-5: To overcome this problem, Hadoop introduces HDFS Federation (a federation of NameNades that statically partition the filesystem namespace), which allows a cluster to scale by adding more NameNodes horizontally, each of which manages a portion of the filesystem namespace (see figure). Namenodes are federated, that is, all these NameNodes work independently and don’t require any co-ordination with each other. You can get detail discussion on HDFS Federation in my post “Hadoop HDFS Federation“. […]
LikeLike
Hi..please clarify on the below
1.If we want to implement High availability along with the federation..should we add one passive name node to each of the namenodes in federation ?
2. In case of federation..will the block report of datanodes to namespace will have only the blockpoll related that specific namespace or it contains all the blockpool information
LikeLiked by 1 person
Apologize! for my late reply. Please find my answer below:
Question 1: Yes. We need to maintain a Passive NameNode for each Active NameNode (each namespace). Please go through my High Availability article for more details. https://hadoopabcd.wordpress.com/2015/02/19/hdfs-cluster-high-availability/
Question 2: Yes. DataNode will only report block report to specific namespace.
LikeLike
Hi I want something as below.
What if I want to share common namespace with two different namenodes with their passive as well (for HA of course).
Can I do something like this ? In short I want namenode to share the load of client requests coming for one namespace.
LikeLike
Appreciate! your comment. If I understood your query correctly, at any point in time, exactly one of the NameNodes is in an Active state for each namespace. It would not be possible to have multiple active NameNodes for a given namespace to serve client requests. So, there is no point to balance load between two or more active NameNodes. You can create N number of namespaces with Active and Passive configuration to balance load. Please let me know if I answered your query.
LikeLike
Good work Sir, Thanks for the proper explanation about HDFS. I found one of the good resource related to HDFS and Hadoop. It is providing in-depth knowledge on HDFS and HDFS Architecture. which I am sharing a link with you where you can get more clear on HDFS and Hadoop. To know more Just have a look at Below link
HDFS
Hadoop
HDFS Architecture
LikeLike