Apache Storm (latest version 0.9.3 ) is an open-source distributed real-time computation system for extremely fast processing large volumes of data that was originally developed at Backtype (later acquired by Twitter) and written in Clojure. Today’s slogan – Data expire fast. Very fast. Before expired, we need to process them.
Here are some typical use cases for Storm
- Bank – Transaction fraud detection
- Telecom – Silent Roamers Detection
- Retail – Inventory Dynamic Pricing
- Social Networking – Trending Topics (cricket update, election update)
Five characteristics make Storm ideal for real-time data processing. Storm is:
- Highly scalable – Horizontally scalable like Hadoop. Thousands of workers per cluster.
- Fault-tolerent – Failure is expected, and embraced. Automatically reassigns tasks on failed nodes. Storm also implements fault detection at the task level, where upon failure of a task, messages are automatically reassigned to quickly restart processing.
- Reliable (Guarantees processing) – Support at least once and exactly once processing semantics. If any failure happen during processing of data, spout will be responsible to resend the data for processing. See figure-1
- Language agnostic – Processing logic can be written in any programming language
- Fast – Storm is built with speed in mind. 1M+ messages/tuples per second per node.
Figure-1: Spout resend the data for reprocessing

Storm key concepts/elements:
- Spouts – Input sources are called Spouts. It transform input data into stream data and pass to bolts. Input data source can be Database, JMS, Redis, Kafka, API, File System etc.
- Bolts – Process stream data are called Bolts. Bolts can be written in any programming languages (Shell, Java, Python etc). Bolt can also produce stream data for it’s down line bolts.
- Topology – A DAG of spouts and bolts are called Topology (A group of spouts and bolts wired together into a workflow). A topology runs forever (or until you kill it, of course), consuming data from the configured sources (Spouts) and passes the data down the processing pipeline (Bolts). A topology can be written in any language including any JVM based language, Python, Ruby, Perl, or, with some work, even C. See figure-3
- Tuples– A tuple (message) is a named list of values, where each value can be any type (primitive or custom).
- Streams – An unlimited (continuous flow) sequence of tuples. Streams originate from spouts. See figure-2
- Stream Grouping – Stream grouping allows Storm developers to control how tuples are routed to bolts in a workflow.
Figure-2: Stream
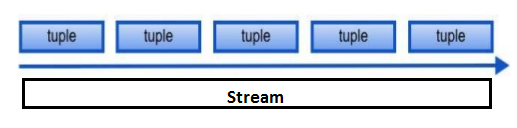
Figure-3: A Storm Topology

For example: Spouts reads tweets from a MQ, and produce (author, tweet, date) and send it to Bolt. (author, tweet, date) is the tuple, and author, tweet, date are three fields of this tuple.
A Storm has 3 key components which made Storm cluster:
- Nimbus (Master node). It’s a storm deamon thread which run on master node. Only one Nimbus node in a cluster.
- Supervisor (Slave/Worker nodes). It’s a storm deamon thread which run on each worker node. Any number of worker nodes in a cluster.
- Zookeper (Storm cluster co-ordinator). Collection of Zookeeper nodes (Zookeeper cluster) which co-ordinate and manage storm cluster.

How Storm Works
- Nimbus node – The master node runs a daemon called “Nimbus” that is similar to Hadoop’s “JobTracker”. Nimbus is responsible for distributing code around the cluster, assigning tasks to worker nodes, and monitors computation and reallocates worker processes as needed.
- ZooKeeper nodes – All coordination between Nimbus and the Supervisors is done through a Zookeeper cluster. It store Storm cluster matrics data.
- Supervisor nodes – Each worker node runs a daemon called the “Supervisor”. The supervisor listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it. Each worker process executes a subset of a topology; a running topology consists of many worker processes spread across many machines.
Note: Storm does not persists any incoming data i.e storm is stateless. The Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This means you can kill -9 Nimbus or the Supervisors and they’ll start back up like nothing happened. This design leads to Storm clusters being incredibly stable.
How parallelism works in a Storm topology:
The throughput (processing speed) of the topology is decided by the number of instances of each component (spout or bolt) running in parallel. This is known as the parallelism of a topology. Storm distinguishes between the following three main entities that are used to actually run a topology in a Storm cluster:
- Worker process (JVM Process)
- Executor (Thread in JVM Process)– An executor is a thread that is spawned by a worker process and runs within the worker’s JVM.
- Task (Instance)– A task performs the actual data processing and is run within its parent executor’s thread of execution. An executor may run one or more tasks for the same component (spout or bolt). An executor always has one thread that it uses for all of its tasks, which means that tasks run serially on an executor. Running more than one task per executor does not increase the level of parallelism but it helps us to rebalance the topology (
storm rebalancecommand) in future.
For example: if you set num of tasks = 4 and executors = 2 then each thread will run 2 tasks. But tasks run serially on executors (each thread will run one task at a time ).As a result even if you have 4 instances of a bolt all of them are not running at one time. So whats the use then ?
Creating multiple task per executor will provide you the flexibility to alter the number of executors using the rebalance command without killing the topology down. So in future if you add extra node to the cluster (or for whatever reason) you can easily change the number of executors to 4 so that now for each task there is a dedicated thread to handle that ( reason why #threads <= #tasks is true, because having more executors than task wont give any benefit). So now each 4 instances of your spout/bolt (called components) can run in parallel at one time . This is how storm scales.
A Topology – Collection of worker processes (i.e. collection of JVM processes). Each worker process should have a unique port.
A Worker process – Collection of executors (i.e. collection of threads). Good design is to assign each thread to one CPU core per node.
An Executor – Collection of tasks (i.e. collection of spouts OR bolts). A task is an instance of a spout or a bolt.
Here is a simple illustration of their relationships:
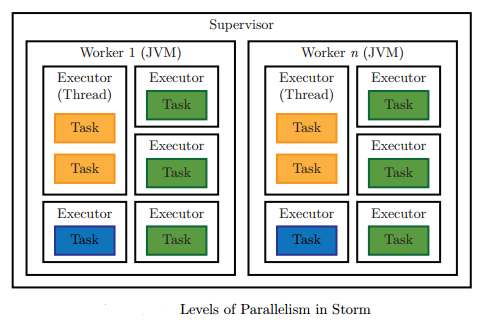
Figure shows parallelism of a topology

So for your reference:
- Task to task communication (inter-thread communication on the same node): LMAX Disruptor with no serialization
- Process to process communication (inter-process node-to-node communication across the network): ZeroMQ / Netty with Kryo serialization
- Topology to topology communication: nothing built into Storm, you must take care of this yourself with e.g. a messaging system such as Kafka/RabbitMQ, a database, etc.
Storm Topology Rebalancing:
A nifty feature of Storm is that you can increase or decrease the number of worker processes and/or executors at runtime without being required to restart the cluster or the topology. The act of doing so is called rebalancing. But the number of tasks of a topology is fixed i.e number of tasks can not be changed while the topology is running. Changing the number of tasks at runtime for a given component (spout or bolt) would complicate the reconfiguration of the communication patterns (stream grouping) among tasks.
By definition which remains unchanged (no. of executors <= no. of tasks). So if your component is having for example (number of executors: 50, number of tasks: 50) then you can not increase the parallelism by increasing the number of executors, however you can decrease it.
There are two ways you can rebalance a topology:
- Use the Storm web UI to rebalance the topology.
- Use the command “storm rebalance".
Note:
- If we add new supervisor/workers nodes to a Storm cluster and don’t rebalance the topology, the new nodes will remain idle.
- You can only increase the parallelism up to the number of tasks.
- If number of executors are greater than the number of tasks then there would be executors without tasks to execute. So, those executors will be idle.
Stream Groupings / Communication Pattern:
There are 8 grouping methods (communication pattern), which defines how the downstream bolt read from the upstream spout/bolt.
- Shuffle grouping – Tuples are randomly distributed across the bolt’s tasks in a way such that each bolt is guaranteed to get an equal number of tuples.
- Fields grouping – The stream is partitioned by the fields specified in the grouping. For example, if the stream is grouped by the “user-id” field, tuples with the same “user-id” will always go to the same task, but tuples with different “user-id”’s may go to different tasks.
- Partial Key grouping: The stream is partitioned by the fields specified in the grouping, like the Fields grouping, but are load balanced between two downstream bolts, which provides better utilization of resources when the incoming data is skewed.
- All grouping – The stream is replicated across all the bolt’s tasks. Use this grouping with care.
- None grouping – This grouping specifies that you don’t care how the stream is grouped. Currently, none groupings are equivalent to shuffle groupings.
- Global grouping – Sends the entire stream to a single bolt task.
- Local grouping: Sends tuples to the consumer bolts in the same executor.
- Custom grouping – You defines your own grouping rule.
Storm Trident::
Trident is a high-level abstraction for doing realtime computing on top of Storm just like Pig on Hadoop. It provide high level API to work with Storm.
- “exactly once” processing semantics of Trident and “at least once” processing semantics of Storm
- Trident provides stateful stream processing and Storm is stateless stream processing framework.
- Trident processes streams in batches, Storm processes streams on per tuple basis.
Trident is an abstraction on storm, just like pig over hadoop, which provides us with various useful functions like grouping, joins, aggregation, filters etc.
Storm source code:

In this article I tried to summarize my own understanding of Storm, which may or may not be 100% correct – feel free to let me know if there are any mistakes in the article above!
LikeLike