Background
When a file is written to HDFS, it is split up into big chucks called data blocks, whose size is controlled by the parameter dfs.block.size in the config file hdfs-site.xml (in my case – left as the default which is 64MB). Each block is stored on one or more nodes, controlled by the parameter dfs.replication in the same file (in most of this post – set to 3, which is the default). Each copy of a block is called a replica.
Replication Pipelining
When writing data to an HDFS file, its data is first written to local cache at client. When the cache reaches a block size (default 64MB), the client request and retrieves a list of DataNodes from the NameNode. This list contains the DataNodes that will host a replica of that block. The number of DataNodes is based on replication factor which is default to 3. The client then organizes a pipeline from DataNode-to-DataNode and flushes the data block to the first DataNode. The first DataNode starts receiving the data in small portions (file system block size 4 KB), writes each portion to its local repository and transfers the same portion to the second DataNode in the list. The second DataNode, in turn starts receiving each portion of the data block, writes that portion to its repository and then flushes the same portion to the third DataNode. Finally, the third DataNode writes the data to its local repository. Thus, a DataNode can be receiving data from the previous one in the pipeline and at the same time forwarding data to the next one in the pipeline. Thus, the data is pipelined from one DataNode to the next. When the first block is filled, the client requests new DataNodes to be chosen from NameNode to host replicas of the next block. A new pipeline is organized, and the client sends the further bytes of the file. This flow continues till last block of the file. Choice of DataNodes for each block is likely to be different.
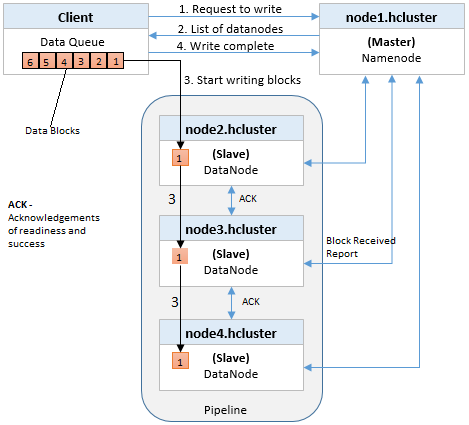
Note: Acknowledgements (ACK) of readiness and success
Before the Client writes “Block A” of File.txt to the cluster it wants to know that all Data Nodes which are expected to have a copy of this block are ready to receive it. It picks the first Data Node in the list for Block A (Data Node 1), opens a TCP 50010 connection and says, “Hey, get ready to receive a block, and here’s a list of (2) Data Nodes, Data Node 5 and Data Node 6. Go make sure they’re ready to receive this block too.” Data Node 1 then opens a TCP connection to Data Node 5 and says, “Hey, get ready to receive a block, and go make sure Data Node 6 is ready is receive this block too.” Data Node 5 will then ask Data Node 6, “Hey, are you ready to receive a block?”
The acknowledgements of readiness come back on the same TCP pipeline, until the initial Data Node 1 sends a “Ready” message back to the Client. At this point the Client is ready to begin writing block data into the cluster.
They will also send acknowledgements of success messages back up the pipeline and close down the TCP sessions. The Client receives a success message and tells the Name Node the block was successfully written. The Name Node updates it metadata info with the Node locations of Block A in File.txt.
Replica Placement Policy
The default block placement policy is as follows:
1. Place the first replica somewhere – either a random rack and node (if the HDFS client is outside the hadoop cluster) or on the local node (if the HDFS client is running on a node inside the cluster).
local node policy :
Copy a file from a local path on one of the data nodes (I used hadoop22) to HDFS:
We expect to see the first replica of all blocks to be local – on node hadoop22.
We can see that:
- Block 0 of file file.txt is on hadoop22 (rack 2), hadoop33 (rack 3), hadoop32 (rack 3)
- Block 1 of file file.txt is on hadoop22 (rack 2), hadoop33 (rack 3), hadoop32 (rack 3)
2. The second replica is written to a different rack from the first, chosen at random.
3. The third replica is written to the same rack as the second replica, but on a different node.
4. If there are more replicas – spread them across the rest of the racks.
Replication Rack Awareness
For a large cluster, it may not be practical to connect all nodes in a flat topology. A common practice is to spread the nodes across multiple racks. Nodes of a rack share a switch, and rack switches are connected by one or more core switches. Communication between two nodes in different racks has to go through multiple switches. In most cases, network bandwidth between nodes in the same rack is greater than network bandwidth between nodes in different racks.
HDFS uses a simple but highly effective policy to allocate replicas for a block. If a process that is running on any of the HDFS cluster nodes open a file for writing a block, then first replica of that block is allocated on the same machine on which the client is running. The second replica is allocated on a randomly chosen rack that is different from the rack on which the first replica was allocated. The third replica is allocated on a randomly chosen datanode on the same remote rack that was chosen in the earlier step. This means that a block is present on two unique racks.
The key rule is that for every block of data, two copies will exist in one rack, another copy in a different rack.
Replication Rack Awareness
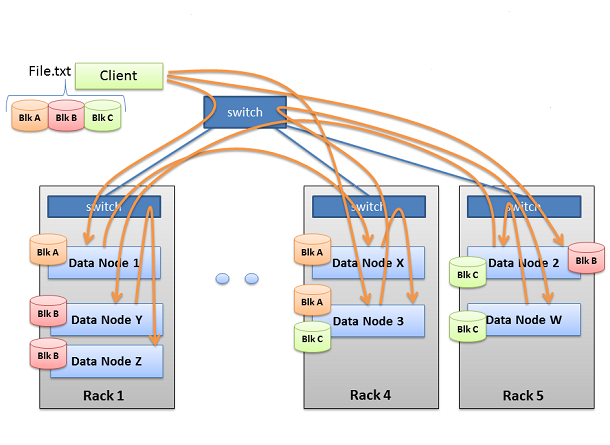

[…] Reducer output file blocks will be replicated in HDFS (DataNodes). Reducer output files (i.e. part-r-00000) are stored on HDFS in Hadoop MapReduce. Each block of reducer output files are maintained in 3 copies (equal to default replication factor). The first replica of reducer output is stored on the local node where reducer is running and other replicas being stored on off-rack nodes. The key rule is that for every block of data, two copies will exist in one rack, another copy in a different rack. You can get more details on block distribution and replication in my previous post “HDFS File Blocks Distribution in DataNodes“. […]
LikeLike
Well Explain.thanks
LikeLike
Well Explain. Please upload hadoop patch
LikeLike