I wanted to get familiar with the big data world, and decided to test Hadoop on Amazon Cloud. It was a really interesting and informative experience. The aim of this blog is to share my experience, thoughts and observations related to both practical and non-practical use of Apache Hadoop.
Overview
A typical Hadoop multi-node cluster
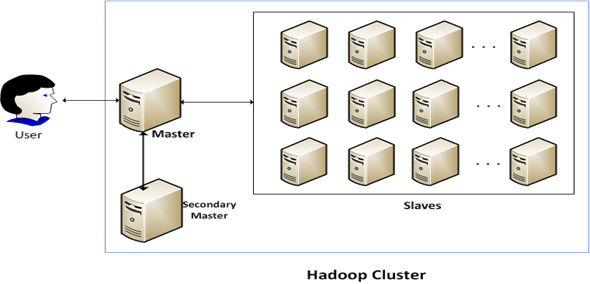
In this post, I am going to cover how to setup multi-node Hadoop cluster on Amazon EC2. We are going to setup 4 node Hadoop cluster on Amazon Cloud as below.
- NameNode (Master)
- SecondaryNameNode (Secondary Master)
- DataNode1 (Slave1)
- DataNode2 (Slave2)
This blog post is divided into four parts:
Part 1 – This first part explain how to setup multi-node Hadoop cluster on Amazon Cloud.
Part 2 – This second part explain the setup up Windows client access to Amazon EC2 Instances.
Part 3 – Now we are ready to introduce Hadoop installation and cluster setup.
Part 4 – We now turn into a sample Hadoop MapReduce word count example using Eclipse.
Preparation
The prerequisites for this blog is that you should have the following:
- Amazon AWS Account
- PuTTy Windows Client (to connect to Amazon EC2 instance)
- FileZilla (File Copy)
Hope you will enjoy my blog posts. Of course, any comments and criticism are warmly welcomed.

Reblogged this on Dinesh Ram Kali..
LikeLike