In this BigData world, massive data storage and faster processing is a big challenge. Hadoop is the solution to this challenge. Hadoop is an open-source software framework for storing and processing big data in a distributed fashion on large clusters (thousands of machines) of commodity (low cost) hardware. Hadoop has two core components, HDFS and MapReduce. HDFS (Hadoop Distributed File System) store massive data into commodity machines in a distributed manner. MapReduce is a distributed data processing framework to work with this massive data.
MapReduce framework designed to process only batch data processing. It is not fit to process real-time data. As today’s market demand big data with stream data processing (faster than real-time). So MapReduce fail to provide solution to this problem. YARN (next generation MapReduce) is the answer. YARN provide solution to process batch, interactive, real-time and stream data as per demand. Classic example like MapReduce is a windows operating system with only notepad and YARN is a windows operating system with Microsoft Office, applications to watch movies, applications to listen music etc.
Apache YARN (Yet Another Resource Negotiator) is Hadoop’s cluster resource management system. YARN was introduced in Hadoop 2.0 to improve the MapReduce implementation, but it is general enough to support other distributed computing paradigms as well.
YARN provides APIs for requesting and working with cluster resources (memory, CPU, disk/network I/O), but these APIs are not typically used directly by user code. Instead, users write to higher-level APIs provided by distributed computing frameworks (MapReduce, Tez, Impala, Storm, Spark etc), which themselves are built on YARN and hide the resource management details from the user. The situation is illustrated in figure below:
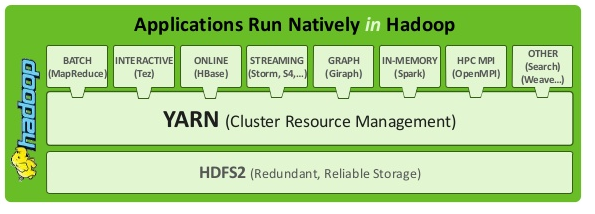
There is a further layer of applications that build on the frameworks shown in above figure. Pig, Hive and Crunch are all examples of processing frameworks that run on MapReduce or Spark or Tez (depends on versions), and don’t interact with YARN directly.
YARN Compared to MapReduce 1.0 (MRv1)
The distributed implementation of MapReduce in the original version of Hadoop (version 1 and earlier) is sometimes referred to as “MapReduce 1(MRv1)” to distinguish it from “MapReduce 2(MRv2)”, the implementation that uses YARN (in Hadoop 2 and later).
In MRv1, there are two types of daemon (background process) that control the job execution process: a jobtracker and one or more tasktrackers. The jobtracker coordinates all the jobs run on the system by scheduling tasks to run on tasktrackers. Tasktrackers run tasks and send progress reports to the jobtracker, which keeps a record of the overall progress of each job. If a task fails, the jobtracker can reschedule it on a different tasktracker.
In MRv1, the jobtracker takes care of both job scheduling (matching tasks with tasktrackers) and task progress monitoring (keeping track of tasks, restarting failed or slow tasks, and doing task bookkeeping, such as maintaining counter totals). By contrast, in YARN these responsibilities are split into separate entities: the resource manager and an application master (one for each MapReduce job).
Limitations in the MapReduce 1 framework
1. The job tracker has two primary responsibilities: i) managing the cluster resources and ii) scheduling all user jobs. As the cluster size and the number of jobs at Facebook grew, the scalability limitations of this design became clear. The job tracker could not handle its dual responsibilities adequately. At peak load, cluster utilization would drop precipitously due to scheduling overhead.
2. Another limitation of the Hadoop MapReduce 1 framework was its pull-based scheduling model. Task trackers provide a heartbeat status to the job tracker in order to get tasks to run. Since the heartbeat is periodic, there is always a pre-defined delay when scheduling tasks for any job. For small jobs this delay was problematic.
3. Static slot allocation : Hadoop MapReduce is also constrained by its static slot-based resource management model. Rather than using a true resource management system, a MapReduce cluster is divided into a fixed number of map and reduce slots based on a static configuration – so slots are wasted anytime the cluster workload does not fit the static configuration (e.g suppose number of MapReduce tasks are configured 10 in the cluster but cluster workload is 6, then 4 slots are wasted). Furthermore, the slot-based model makes it hard for non-MapReduce applications to be scheduled appropriately.
4. Finally, the original job tracker design required hard downtime (all running jobs are killed) during a software upgrade, which meant that every software upgrade resulted in significant wasted computation.
YARN and MapReduce 2.0 (MRv2)
The simplest way to understand the difference between Hadoop 1.x and Hadoop 2.x is that the architecture went from being a single use system that only handled Batch jobs to a multi-purpose (multi-tenancy) system that could not only run the batch jobs that Hadoop 1.x did but also more interactive, online, streaming jobs as well.
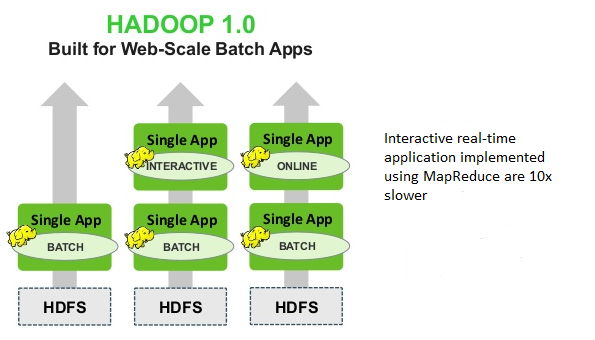
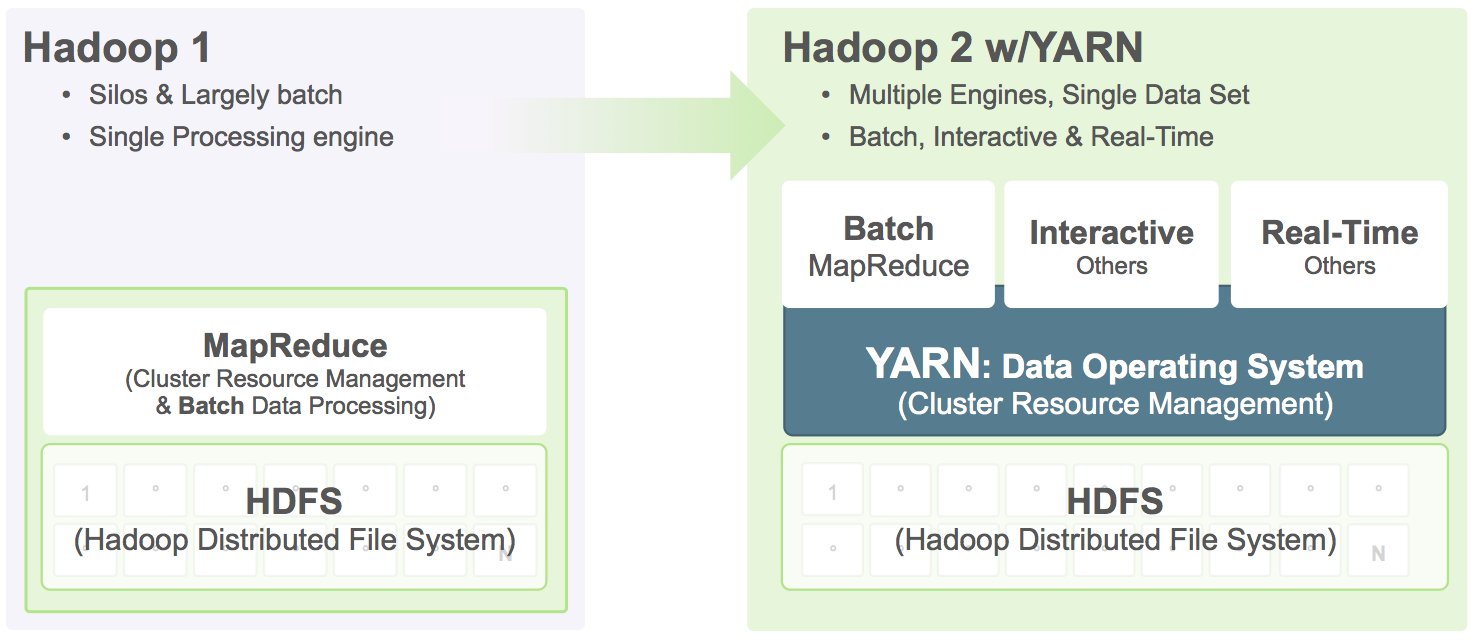
In Hadoop 1.x, everything that was submitted to cluster only for batch processing. In Hadoop 2.x (YARN), their can be any type of processing like interactive, real-time, online, streaming and even batch processing.
NOTE : It’s important to realize that the old and new MapReduce APIs are not the same thing as the MapReduce 1 and MapReduce 2 implementations. MRv1 and MRv2 are two different framework with two different implementations. The APIs are user-facing client-side features and determine how you write MapReduce programs, whereas the implementations are just different ways of running MapReduce programs. All four combinations are supported: both the old and new MapReduce APIs run on both MRv1 and MRv2.
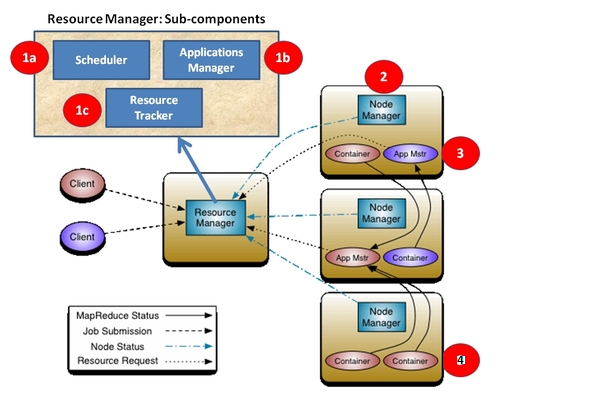
YARN components and their sub-components:
1. Resource Manager (per-cluster)
- 1.a Scheduler (Capacity or Fair scheduler)
- 1.b Applications Manager
- 1.c Resource Tracker
2. Node Manager (per-machine)
3. Application Master (per-application)
4. Container (per-task)
1. Resource Manager (RM)
The ResourceManager is the per-cluster master and long running deamon in NameNode or in separate machine, which is responsible for tracking the resources (memory, CPU, disk/network I/O) in a cluster, and scheduling applications (e.g., MapReduce jobs).
- 1.a Scheduler: Scheduler is a pure scheduler in the sense that it only performs scheduling job based on resource status (memory, CPU, disk/network I/O), no monitoring or tracking of status for the job i.e. it doesn’t attempt to provide fault-tolerance (failure of resources affects job execution fatally) for resources. We shifted that to become a primary responsibility of the ApplicationMaster instance. It optimizes for cluster utilization (keep all resources in use all the time). The Scheduler is pluggable and allows for different algorithms. There are currently two scheduler, one is Capacity scheduler and another is Fair scheduler. Capacity Scheduler is used by default. I will cover YARN schedulers in details in another post.
- 1.b Applications Manager: Responsible for maintaining a collection of submitted applications. Also keeps a cache of completed applications so as to serve users’ requests via web UI or command line long after the applications in question finished.
- 1.c Resource Tracker: Contains settings such as the maximum number of Applications Master retries, how often to check that containers are still alive, and how long to wait until a Node Manager is considered dead.
ResourceManager works together with the per-node NodeManagers and the per-application ApplicationMasters.
2. Node Manager (NM)
The NodeManager is the per-machine slave (same as per-node agent) and long running deamon in DataNode, which is responsible for launching the applications’ containers, monitoring resource usage (memory, CPU, disk/network I/O) of individual containers, tracking node-health and reporting the same to the ResourceManager. NodeManager take instructions from the ResourceManager and manage resources available on a single machine.
On startup, this component registers with the ResourceManager and sends information about the resources available on the nodes. Subsequent NodeManager-ResourceManager communication is to provide updates on container statuses – new containers running on the node, completed containers, etc. Accepts requests from ApplicationMasters to start new containers, or to stop running ones. It also maintains a pool of threads to prepare and launch containers as quickly as possible.
Every NodeManager in a YARN cluster periodically sends a heartbeat request to the ResourceManager—by default one heartbeat per second. Heartbeats carry information about the node manager’s running containers and the resources available for new containers, so each heartbeat is a potential scheduling opportunity for an application to run a container.
3. Application Master (AM)
The ApplicationMaster is, in effect, an instance of a framework-specific library and is responsible for negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the containers and their resource consumption.
Every application has its own instance of an ApplicationMaster which runs for the duration of the application. However, it’s completely feasible to implement an ApplicationMaster to manage a set of applications (e.g. ApplicationMaster for Pig or Hive to manage a set of MapReduce jobs).
An application (via the ApplicationMaster) can request resources to satisfy its resource need with highly specific requirements as depicted in the picture below:
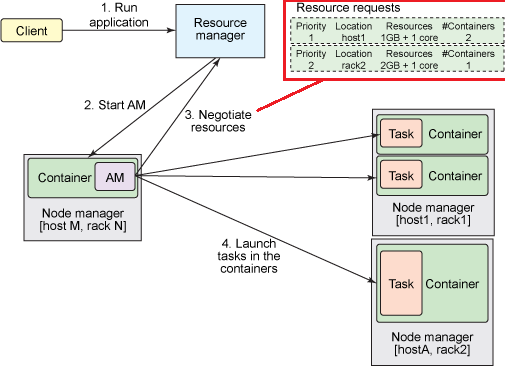
4. Container
A Container is an abstract notion in YARN platform. It represents a collection of physical resources which could mean CPU cores, disk along with RAM.
When an application is about to get submitted into the YARN platform, the YARN client allocates a container from the ResourceManager, where its ApplicationMaster will run. ApplicationMaster itself run on a individual container. After the ApplicationMaster gets started, it should request for more containers to ResourceManager to deploy the tasks and to actually start the application (e.g. MapReduce, Pig, Hive, HBase, Tez, Storm etc. are applications).
A MapReduce job has a specific (built in) ApplicationMaster (called MRAppMaster), which runs on a specific container, called container 0, and each mapper and reducer runs on its own container to be accurate. The ApplicationMaster allocates these containers for the mappers and reducers as it sees fit. To execute the actual map or reduce task, YARN will run a JVM within the container.
In YARN an application (via the ApplicationMaster) can ask for containers spanning any number of memory (RAM) chunks, they can ask for varied number of container types (CPU,Disk) also. The ApplicationMaster, usually, asks for specific hosts/racks with specified container capabilities. Example: The ApplicationMaster can request for containers to ResourceManager’s scheduler with appropriate resource requirements, inclusive of specific machines. They can also request for multiple containers on each machine. All resource requests are subject to capacity constraints for the application, it’s queue etc. The ApplicationMaster is responsible for computing the resource requirements of the application e.g. input-splits for MapReduce applications, and translating them into the protocol understood by the Scheduler. The protocol understood by the scheduler is <priority, (host,=”” rack,=”” *),=”” memory,=”” #containers=””>.
Diagram showing YARN components
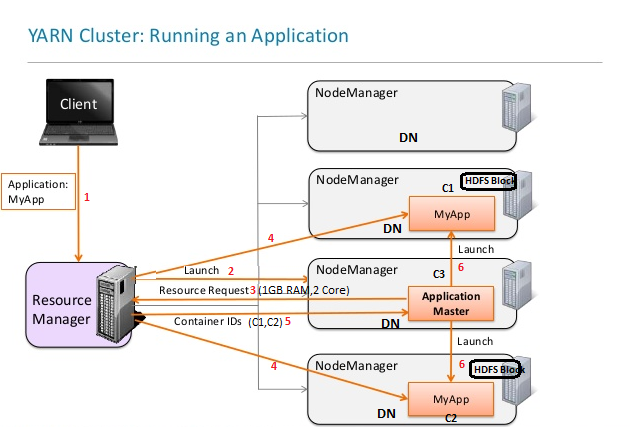
YARN Application Run Flow
After discussed with YARN components and it’s sub-components above, here is the flow to run an application on YARN:
YARN Resource Scheduling
Let’s explore with an example. Let’s say each node in your cluster has 24GB of memory and 6 CPU cores (physical cores and vcores are same for now but in future it will enable finer-grained resource configuration). Other services (operating system + none hadoop applications) running on the nodes require 4GB and 1 core, so you set yarn.nodemanager.resource.memory-mb to 20480 (i.e. 20GB) and yarn.nodemanager.resource.cpu-vcores to 5 cores in yarn-site.xml. If you leave the map and reduce task defaults of 1024MB (i.e. 1GB) and 1 virtual core intact, you will have at most 5 tasks running at the same time. If you want each of your tasks to use 5GB, you would set their mapreduce.(map|reduce).memory.mb to 5120 (i.e. 5GB), which would limit you to 4 tasks running at the same time.
Resource Locality
All the YARN ResourceManager schedulers try to honor locality requests i.e. the application would request a container on one of the nodes hosting the HDFS file block’s three replicas. On a busy cluster, if an application requests a particular node then there is a good chance that other containers are running on it at the time of the request. The obvious course of action is to immediately loosen the locality requirement and allocate a container on the same rack OR any rack and any node in the cluster.
Dominant Resource Fairness
By default DefaultResourceCalculator is used. It considers only memory and ignored CPU. Use DominantResourceCalculator, It uses both CPU and memory.
The way that the schedulers in YARN address both resource type (memory and CPU) is to look at each user’s dominant resource and use it as a measure of the cluster usage, a technique called Dominant Resource Fairness, or DRF for short. The idea is best illustrated with a simple example.
Imagine a cluster with a total of 100 CPUs and 10 TB of memory. Application A requests containers of (2 CPUs, 300 GB), and application B requests containers of (6 CPUs, 100 GB). A’s request is (2%, 3%) of the cluster, so memory is dominant since its proportion (3%) is larger than CPU (2%). B’s request is (6%, 1%), so CPU is dominant. Since B’s container requests are twice as big in the dominant resource (6% versus 3%) it will be allocated half as many containers under fair sharing.
Set below config in capacity-scheduler.xml
yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
YARN Resource Calculator
No of container per node (8) = yarn.nodemanager.resource.memory-mb (8192 MB) / yarn.scheduler.minimum-allocation-mb (1024 MB – container memory)
Summary
When you have a YARN cluster, it has a YARN Resource Manager daemon that controls the cluster resources (practically memory) and a series of YARN Node Managers running on the cluster nodes and controlling node resource utilization. From the YARN standpoint, each node represents a pool of RAM that you have a control over. When you request some resources from YARN Resource Manager, it gives you information of which Node Managers you can contact to bring up the execution containers for you. Each execution container is a JVM with requested heap size. JVM locations are chosen by the YARN Resource Manager and you have no control over it – if the node has 64GB of RAM controlled by YARN (yarn.nodemanager.resource.memory-mb setting in yarn-site.xml) and you request 10 executors with 4GB each, all of them can be easily started on a single YARN node even if you have a big cluster.
Each node dedicates some amount of memory (via the yarn.nodemanager.resource.memory-mb setting) and CPU (via the yarn.nodemanager.resource.cpu-vcores setting) to YARN for any YARN application.
A MapReduce job is a YARN application and each Map and Reduce task will run in a separate container, it asks YARN for containers to run its map and reduce tasks, via the settings mapreduce.[map|reduce].memory.mb and mapreduce.[map|reduce].cpu.vcores. Container requests to YARN from other YARN applications (other than MapReduce application, e.g. Tez, Impala etc) through resource requests (<priority, (host,=”” rack,=”” *),=”” memory,=”” #containers=””>) protocol.
The memory provided to a mapper or reducer process by the NodeManager is specified to YARN via the per-job mapreduce.[map|reduce].memory.mb. However, the JVM itself has memory overhead. So the heap size available to the mapper or reducer is determined by settings such as mapred.[map|reduce].child.java.opts, which specifies the heap size for the launched Java process. When resources allocated by YARN don’t match the resources consumed by the MR2 job, you’ll see either cluster underutilization (resource consumption is less than resource allocation) or jobs being killed (resource consumption is greater than resource allocation).
In MR1, the number of concurrent tasks launched per node was specified via the settings mapred.map.tasks.maximum and mapred.reduce.tasks.maximum. In this case, 1 task can consumes all the available resources, then rest of the tasks are wasted. In MR2, one can determine how many concurrent tasks are launched per node by dividing the resources allocated to YARN by the resources allocated to each MapReduce task. In this case, 1 task can only consumes resources allocated to it.

Requesting all my readers to provide your valuable comments to help me build well structured content and easy to understand. Any suggestions and criticism is warmly welcome.
LikeLike
Thank You Bikash for a great explanation. As usual all your articles are very detailed and good to understand.
LikeLike
Thank You Venkat. Nice to see your comment.
LikeLike
Bikash, thanks for such a detailed explanation however, a serious problem that I see is the lack of practical implementation..! All this theory with no real world use cases is off no good.
Thanks anyway
LikeLike