Prior to Hadoop 2.x (Hadoop 1.x), the NameNode was a single point of failure (SPOF) in an HDFS cluster. Each cluster had a single NameNode, and if that machine or process became unavailable, the cluster as a whole would be unavailable until the NameNode was either restarted or brought up on a separate machine.
- In the case of an unplanned event such as a machine crash, the cluster would be unavailable until an operator restarted the NameNode.
- Planned maintenance events such as software or hardware upgrades on the NameNode machine would result in periods of cluster downtime.
The HDFS High Availability (HA) feature addresses the above problems by providing the option of running two redundant NameNodes in the same cluster in an Active/Passive configuration with a hot standby. This allows a fast failover to a new NameNode in the case that a machine crashes, or a graceful administrator-initiated failover for the purpose of planned maintenance. In order for the Standby node to keep its state synchronized with the Active node, the two nodes both have access to a directory on a shared storage device. The Active NameNode play a writer role and Standby NameNode play a reader role.
Now let us look at various HA options available:
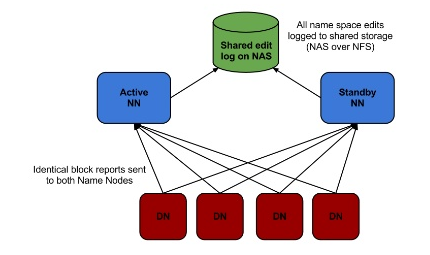
1. Shared Storage using NFS
2. Quorum-based Storage
1. Shared Storage using NFS (edit log on NAS/SAN)
Avoid split-brain – Both NN think they are active and try to write to the same file. As a result, your data become corrupt. – Custom fencing script address the problem
Configure a fencing script – which is able to either
(a) power off the previously active node, or
(b) prevent further access to the shared mount by the previously active node.
**Now it avoided the planned downtime (software or hardware upgrade) by allowed the operator to manually trigger failover to the standby.
Problems with this approach:
- Manual failover only – Requires an operator to take action quickly after a crash.
- Requirement of a NAS/SAN device made deployment complex, expensive and error-prone.
- NAS itself a single point of failure.
- Fencing configuration is too complicated and easy to misconfigure.
- It does not address the unplanned downtime (software or hardware or network faults).
Need another solution which address the below points:
- Automatic failover – Introduced ZooKeeper addressed the automatic failover problem.
- Remove dependency on external hardware or software (NAS/SAN, Linux-HA)
- Address both planned and unplanned downtime.
Figure shows Shared storage with ZooKeeper:

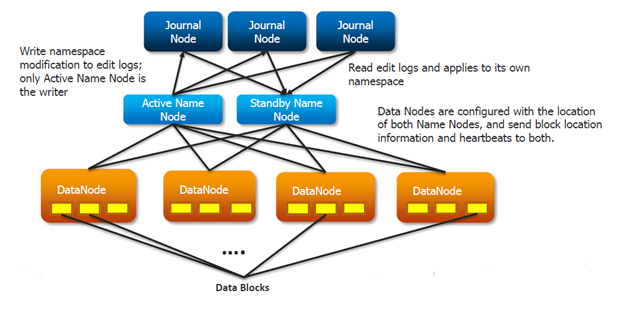
2. Quorum-based Storage
The design relies upon the concept of quorum commits to a cluster of daemons, termed JournalNodes. Each JournalNode exposes a simple RPC interface, allowing a NameNode to read and write edit logs stored on the node’s local disk. When the NameNode writes an edit, it sends the edit to all JournalNodes in the cluster, and waits for a majority (quorum) of the nodes to respond. Once a majority have responded with a success code, the edit may be considered committed.
2.1 QuorumJournalManager (client)
- Provides interface between NameNode and JournalNodes through RPC.
- This component implements the already-pluggable JournalManager interface present in HDFS.
- It uses the existing FileJournalManager implementation to manage its local storage.
2.2. JournalNode (server)
- Standalone light weight daemon running on an odd number of nodes.
- Provides actual storage of edit logs on local disk.
- No need for extra hardware. The nodes will run on the same physical hardware as (1) the NameNode, (2) the Standby NameNode, and (3) the JobTracker.
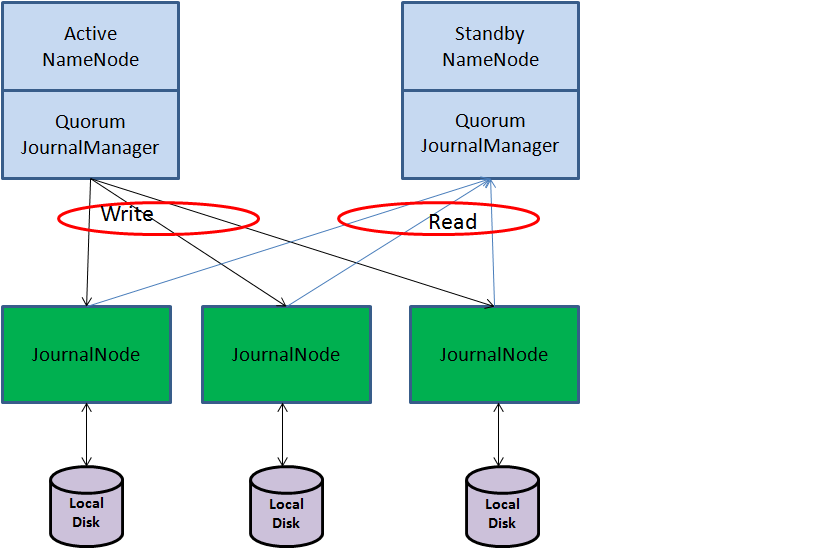
Avoid split-brain – Both NN think they are active and try to write to the same file. As a result, your data become corrupt. – JoutnalNode fencing with epoch number address the problem.
JournalNode fencing
- When a NameNode becomes active, it is assigned an integer epoch number.
- Each epoch number is unique. No two NameNode have the same epoch number.
- When a NameNode sends any message to a JournalNode, it includes its epoch number as part of the request.
- Whenever the JournalNode receives such a message, it compares the epoch number against a locally stored value called the promised epoch number.
- If the requester’s epoch number is higher than the locally stored promised epoch number, then it is said to be “newer” and accept the edit request and also update it’s previous promised epoch number with the new epoch number.
- If the requester’s epoch number is lower, then it will reject the request.
- For any NameNode to successfully write edits, it has to successfully write to a majority of nodes. That means that a majority of nodes have to accept its epoch number as the newest.
- When a new NameNode becomes active, it is guarantee has an epoch number higher than any previous NameNode.
Figure shows Quorum Journal with ZooKeeper:

Solution with this approach
- No extra hardware cost. Use existing physical machines.
- Fencing is now implicit. Avoided error-prone custom configuration.
- Automatic failover – ZooKeeper addressed the automatic failover problem.
Number of tolerate failure = (Number of JN – 1) / 2

[…] Solution-4: The HDFS High Availability feature addresses the above problems by providing the option of running two NameNodes in the same cluster, in an Active/Passive configuration. These are referred to as the Active NameNode and the Standby NameNode. Unlike the Secondary NameNode, the Standby NameNode is hot standby, allowing a fast failover to a new NameNode in the case that a machine crashes, or a graceful administrator-initiated failover for the purpose of planned maintenance. In a typical HA cluster, two separate machines are configured as NameNodes. At any point in time, one of the NameNodes is in an Active state, and the other is in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standby is simply acting as a slave, maintaining enough state (through checkpointing process) to provide a fast failover if necessary. You can get detail discussion on HDFS HA feature in my previous post “Hadoop HDFS High Availability“. […]
LikeLike
In Hight availability name node, Please explain about Secondary NameNode work.
For merge edit logfile which journal node it will take. 1st node or all journal edit logfiles?
LikeLike
Very useful information, have achieved a great knowledge from the above content on Hadoop Training useful for all the aspirants of Hadoop Training.
https://www.kellytechno.com/Hyderabad/Course/Hadoop-Training
LikeLike
Who is generating epoch number ?
LikeLike
Whenever a NameNode becomes active from a failover, it first generate an epoch number.
LikeLike